通过认证
通过认证
“语音识别模块,语音识别芯片”参数说明
| 认证: | CE | 封装: | SMD |
| 功能结构: | 数/模混合集成电路 | 制作工艺: | 半导体集成电路 |
| 导电类型: | 双极型 | 外形: | 扁平型 |
| 集成度高低: | 大规模集成电路 | 应用领域: | 标准通用 |
| 型号: | Wtk6900b01 | 规格: | 普遍适用 |
| 商标: | 唯创 | 产量: | 2000000 |
“语音识别模块,语音识别芯片”详细介绍
1、产品特征
?半米内识别率90%以上
?可以通过语音指令控制输出
?可以通过单片机串口控制播放指定语音
?三种输出模式:串口输出、IO输出、喇叭播放
?PWM输出可直接推动0.5W/8Ω或1W/8Ω扬声器
?具有差分放大电路,安静环境下语音识别距离可达到2-3米
?外挂SPI Flash,增加存储容量
?可以存储多组词条,但是同一时刻只能出现一组词条
?非特定人语音识别
?语音支持32种语言,如中文、英语、粤语、日语等
2、功能描述
WTK6900B01语音识别模块是一款小巧语音识别模块,安静环境下语音识别距离可达到2-3米;外挂SPI Flash,增加存储容量;主要功能如下:
?识别功能:可识别预设的语音词条,同时通过串口,IO输出以及识别结果
?播放功能:通过单片机指令播放指定的语音,同时通过BUSY脚标志是否正在播放语音
3、应用范围
?高端玩具类:鹦鹉学舌、讲故事机、音乐播放机等
?开关类:灯的开关及亮度调节等
?语音播报:小家电提示音等
?语音导航:医院、商场等地方内指路器
8、模块功能详解
8.1 IO口功能简介
?RXD/TXD 标准串口通信、波特率 9600,配置见图3
?11脚为播放状态BUSY指示,播放时为H,不播放时为L
?MIC 麦克风正极输入端,可接常用的麦克风型号
?PWMP/PWMN pwm输出、可直接驱动0.5W/8Ω或1W/8Ω扬声器
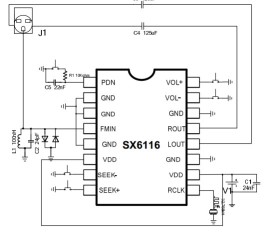
图3串口配置图
8.2指令格式
串口指令格式采用:起始码+参数+反码,设置如下表3.
表3指令格式表
起始码 参数 反码
AA/BB 见下文 见下文
注:①参数+反码=FF,例如TX输出的指令“AA 01 FE”,起始码为AA,参数为01,反 码为FE,01+FE=FF,其他数据依此类推
②TX输出指令起始码为AA(见表4),RX输入指令起始码为BB(见表5)
8.3词条相关简介
WTK6900B01语音识别模块可以实现固定词汇,非特定人的语音识别。
固定词汇并非指词条永远无法改变,而是用户不可以自行更改,但开发者可以根据需求更换词条,之后将词条存储到WTK6900A-24SS语音芯片里或是外挂的SPI Flash里,待识别时将会拿输入的语音与存储起来的词条语音作对比,若是两者相似度达到标准就认为是输入的语音与存储中的词条一致,即识别成功。那词条可以存储多少?存储的方式又有多少种?语音对比又是对比什么呢?相似度的标准又是多少?如何知道是否识别成功呢?
8.3.1词条的存储容量
存储词条的地方有两处:语音芯片的内部、SPI Flash;两者本身的容量不同,所能存储的词条数量自然也不同。下面进行四字词条(即是每个词条四个字)的存储容量的对比
存储位置 存储词条数量
WTK6900A-24SS语音芯片 20条左右
SPI Flash 根据Flash自身容量决定
虽说WTK6900A-24SS语音芯片内部可以存储20条左右的词条,但是存储的数量越多,运算的速率越低,识别的效果也会相对的差一点。
8.3.2词条的存储方式
词条的存储方式主要有两种:
①一组存储
在词条的数量较少,并且都是同一类型,如都是表示颜色的词条,那可以选择放在同一组中,不用进行切换,更省时间。
②分组存储
若是词条的数量多,并且分类不一样,那可以选择分组存储,例如现在有三组不同类型的词条,分别是故事类,古诗类以及音乐类
故事类 古诗类 音乐类
海的女儿 春居杂兴 龙的传人
哈利波特 登飞来峰 因为爱情
白雪公主 雨后池上 情非得已
狼和小羊 夏日绝句 独家记忆
将词条分组存储,待需要进行古诗类词条时,则需先进入古诗类词组,那么我们需要一个入口,
?半米内识别率90%以上
?可以通过语音指令控制输出
?可以通过单片机串口控制播放指定语音
?三种输出模式:串口输出、IO输出、喇叭播放
?PWM输出可直接推动0.5W/8Ω或1W/8Ω扬声器
?具有差分放大电路,安静环境下语音识别距离可达到2-3米
?外挂SPI Flash,增加存储容量
?可以存储多组词条,但是同一时刻只能出现一组词条
?非特定人语音识别
?语音支持32种语言,如中文、英语、粤语、日语等
2、功能描述
WTK6900B01语音识别模块是一款小巧语音识别模块,安静环境下语音识别距离可达到2-3米;外挂SPI Flash,增加存储容量;主要功能如下:
?识别功能:可识别预设的语音词条,同时通过串口,IO输出以及识别结果
?播放功能:通过单片机指令播放指定的语音,同时通过BUSY脚标志是否正在播放语音
3、应用范围
?高端玩具类:鹦鹉学舌、讲故事机、音乐播放机等
?开关类:灯的开关及亮度调节等
?语音播报:小家电提示音等
?语音导航:医院、商场等地方内指路器
8、模块功能详解
8.1 IO口功能简介
?RXD/TXD 标准串口通信、波特率 9600,配置见图3
?11脚为播放状态BUSY指示,播放时为H,不播放时为L
?MIC 麦克风正极输入端,可接常用的麦克风型号
?PWMP/PWMN pwm输出、可直接驱动0.5W/8Ω或1W/8Ω扬声器
图3串口配置图
8.2指令格式
串口指令格式采用:起始码+参数+反码,设置如下表3.
表3指令格式表
起始码 参数 反码
AA/BB 见下文 见下文
注:①参数+反码=FF,例如TX输出的指令“AA 01 FE”,起始码为AA,参数为01,反 码为FE,01+FE=FF,其他数据依此类推
②TX输出指令起始码为AA(见表4),RX输入指令起始码为BB(见表5)
8.3词条相关简介
WTK6900B01语音识别模块可以实现固定词汇,非特定人的语音识别。
固定词汇并非指词条永远无法改变,而是用户不可以自行更改,但开发者可以根据需求更换词条,之后将词条存储到WTK6900A-24SS语音芯片里或是外挂的SPI Flash里,待识别时将会拿输入的语音与存储起来的词条语音作对比,若是两者相似度达到标准就认为是输入的语音与存储中的词条一致,即识别成功。那词条可以存储多少?存储的方式又有多少种?语音对比又是对比什么呢?相似度的标准又是多少?如何知道是否识别成功呢?
8.3.1词条的存储容量
存储词条的地方有两处:语音芯片的内部、SPI Flash;两者本身的容量不同,所能存储的词条数量自然也不同。下面进行四字词条(即是每个词条四个字)的存储容量的对比
存储位置 存储词条数量
WTK6900A-24SS语音芯片 20条左右
SPI Flash 根据Flash自身容量决定
虽说WTK6900A-24SS语音芯片内部可以存储20条左右的词条,但是存储的数量越多,运算的速率越低,识别的效果也会相对的差一点。
8.3.2词条的存储方式
词条的存储方式主要有两种:
①一组存储
在词条的数量较少,并且都是同一类型,如都是表示颜色的词条,那可以选择放在同一组中,不用进行切换,更省时间。
②分组存储
若是词条的数量多,并且分类不一样,那可以选择分组存储,例如现在有三组不同类型的词条,分别是故事类,古诗类以及音乐类
故事类 古诗类 音乐类
海的女儿 春居杂兴 龙的传人
哈利波特 登飞来峰 因为爱情
白雪公主 雨后池上 情非得已
狼和小羊 夏日绝句 独家记忆
将词条分组存储,待需要进行古诗类词条时,则需先进入古诗类词组,那么我们需要一个入口,